A lesson from EA expert Sameer Paradkar
Enterprise applications are usually born as monoliths. This practice seems reasonable since the support is less demanding and the system works well from a limited scopes. Microservices take precedence, however, once a system grows too large and complex. A common practice is to break the monolith into small autonomous pieces, each deployed and sustained by an agile team while leaving the team collaboration issues behind.
When a business application, and a development team, get bigger and reach a certain size, companies face a critical management and cooperation bottleneck. Moreover, if a software product is based on a massive monolith architecture, technological challenges are also faced. In such cases, businesses require a solution to fix the workflow and enhance collaboration on the project. A microservice architecture is an answer to the problems associated with the traditional back-end monolith once its complexity calls for higher scalability.
Enterprises usually embrace this kind of solution only when the practical need occurs. In most cases, a development team of more than 20-25 members starts suffering from collaboration difficulties while maintaining the monolith applications. So, the initiative to adopt microservices often comes from the development team or a software vendor.
Key Drivers for Microservices Architecture
Microservices were born to respond to the demands of the modern market. Businesses must analyze their data, innovate, and launch new products and services better and faster than their competitors. They need to be flexible to meet the changing needs of their customers. Migration to microservice architecture enables them to do this more efficiently. Primary drivers for re-architecting a monolithic system into microservices are:
- Business growth: As the application serves more customers and processes more transactions, it needs more capacity and resources.
- Traffic peaks: Ideally, the system should be able to scale automatically, or at least dynamically, in a way that the infrastructure is not pushed to max capacity to support peak traffic. Scaling monolithic applications can often be a challenge.
- Faster time-to-market: There is significant value to the business when adding or modifying a feature takes days or weeks instead of months and doesn't require excessive (and often expensive) regression testing.
- Domain Expertise: Monolithic applications can evolve into a “big ball of mud”; a situation where no single developer or group of developers understands the entirety of the application.
- Re-use: Limited re-use is realized across monolithic applications.
- Operational Agility: It’s challenging to achieve operational agility in the repeated deployment of monolithic application artifacts.
- Tool Set: By definition, monolithic applications are implemented using a single development stack, i.e., Java EE or Dot NET, which can limit the availability of the right tool for the job.
- Agility: The complexity of adding new functionalities on top of the existing monolith application.
Migrating a monolithic application to microservices architecture
This section describes various alternatives to consider when migrating to microservices architecture.
1. Deployment
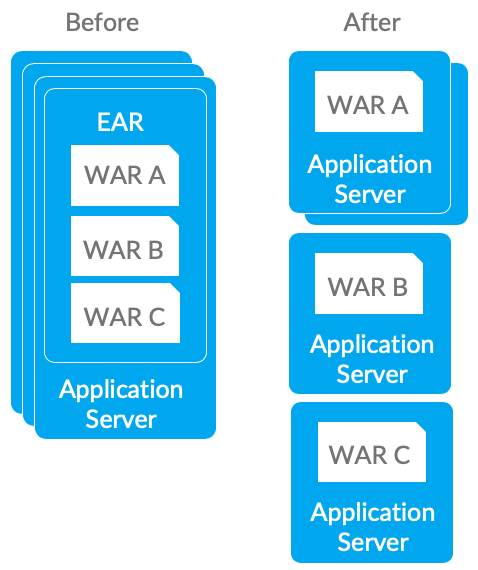
Revisiting the Java application packaging structure and adopting new packaging practices before you start to change the code. In the early 2000s, we all started building ever-larger EAR files to contain our logical applications. We then deployed those EARs across every WebSphere Application Server. The problem is that this tied each piece of code in that application to the same deployment schedules and the same physical servers. Changing anything meant re-testing everything, and that made any changes too expensive to consider. But now with containers like Docker and PaaS, and lightweight Java servers like WebSphere Liberty, the dynamics have changed. So now you can start reconsidering the packaging…
Here are three principles you need to start applying:
- EARs Packaging: Instead of packaging all the related WARs in one EAR, split them up into independent WARs. This may involve minor changes to the code, or more likely to static content, if you change application context roots to be separate.
- Containers: Next apply the "Container per service" pattern and deploy each WAR in its own Liberty server, preferably in its own container (such as a Docker container). One can then scale containers independently.
- DevOps: Once they are split, you can then manage each WAR independently through an automated DevOps pipeline (such as Delivery Pipeline). This is a step toward gaining the advantages of continuous delivery, i.e., build, deploy and manage independently.
![Best Practices to Define Data Objects [Poster]: Learn best practices on how to model data objects and achieve your data map quickly! »](https://no-cache.hubspot.com/cta/default/2570476/cc72efa8-776f-4cde-bf88-7644c84c06b4.png)
2. Application Architecture
Validate any opportunities to refactor the WARs to even more granular levels. Here are three cases where you can find opportunities for refactoring your code to accommodate a packaging approach that packages microservices independently.
- REST or JMS services: One may have existing services that are already compatible with a microservices architecture, or that could be made compatible. Start by untangling each REST or simple JMS service from the rest of the WAR, and then deploy each service as its own WAR. At this level, duplication of supporting JAR files is fine; this is still mostly a matter of packaging.
- SOAP or EJB services: In this case, functionally-based services design should be refactored into an asset-based services design. As in many cases, the functions in the Service Façade will be implemented initially as CRUD (create, retrieve, update, and delete) operations on a single object. The mapping to a RESTful interface is simple: just re-implement the EJB session bean interface or JAX-WS interface. Convert object representations to JSON, which is not very difficult, especially where you were already using JAX-B for serializations.
- Servlet/JSP interfaces: Many Java programs are just simple Servlet/JSP front-ends to database tables. They may not have what is referred to as a "Domain Object" Layer at all, especially if they follow design patterns like the Active Record pattern. In this case, creating a domain layer that you can then represent as a RESTful service is an excellent first step. Identifying your domain objects by applying Domain Driven Design will help you identify your missing domain services layer. Once you've built that and packaged the new service in its own WAR, then you can either refactor the existing Servlet/JSP application to leverage the new service, or you can build a whole new interface.
In the existing landscape based on SOA services, the Web services may be implemented to use RESTful protocols, but it's just as common to find service implementations in SOAP. The starting point is to adopt one standard protocol for service access: REST. In case you have existing Web services already supporting REST, you're done with this step.
- Monolithic without any Web services: Begin there and see if you can separate the business logic into RESTful Web services. Or if you do have Web services, but they are based on SOAP, you'll need to refactor your functionally-based SOAP interfaces to entity-based REST interfaces. Once you've refactored to REST, you'll want to make sure that you can document and catalog your REST services. Tools like Swagger will be helpful in such scenarios.
- Container per Service: After agreeing on REST and documenting your interfaces, the next step is to begin splitting the services apart. Make sure you're doing your best to follow functional decomposition and working toward achieving one container per service. Adopting the "one container per service" strategy may require you to adopt supporting technologies like Cloud Foundry or Docker. Similarly, the one-container-per-service strategy may require you to move from traditional middleware like WebSphere ND to WebSphere Liberty. Set up the right infrastructure for monitoring and logging to be able to support this approach. In any case, you'll want to standardize on one strategy for tracking how your services are being used and how they are performing.
3. Data Architecture
Refactoring the data structures that your applications are built on is the hardest problem in adopting microservices. There are a few guidelines one can follow for these cases:
- Reference Data: A typical pattern in object-relational mapping systems is the combination of reference data in a table sucked into an in-memory cache. Reference data consists of things that are not often updated but is continually read. This kind of data is commonly used to populate drop-downs in GUIs. The typical pattern is to start by reading the list from a table each time it is needed. However, the performance of this pattern is prohibitive, so instead, the system reads it into an in-memory cache like Ehcache at startup. Whenever you have this problem, it is begging to be refactored into a more straightforward, faster-caching mechanism. If the reference data is independent of the rest of your database structure (and it often is, or rather, at most, loosely coupled…), then splitting the data and its services away from the rest of your system can help.
- Master Data management – MDM: MDM it's the same principle that you shouldn't have multiple views of an essential concept like a "customer" in an enterprise. MDM tools help you combine all these different views of the ideas and thus eliminate the unnecessary duplication. The difference is that the MDM solutions are data-centric rather than API-centric. However, a common outcome of applying an MDM solution is to create a centralized set of APIs to represent the access to those concepts through the MDM tool. Treat those APIs as the foundation of a microservices-based approach where the implementation isn't done in the same tool.
- Flat Object Structure: If the object you are mapping to a database is completely flat with no relationships to other objects (with the limited exception of nested objects), then you probably aren't taking advantage of the full capabilities of the relational model. In fact, you are much more likely to be storing documents, such as electronic versions of paper documents like customer satisfaction surveys, problem tickets, etc. In that case, a document database like Cloudant or MongoDB is probably a better option. Splitting your code out into services that work on that type of database will result in much simpler code that is easier to maintain.
- Independent Tables: Begin by looking at the database tables that your code uses. If the tables used are either independent of all other tables or come in a small, isolated "island" of a few tables joined by relationships, then you can just split those out from the rest of your data design. Once you have done that, you can consider the right option for your service, and, depending on the kinds of queries you perform on your data, decide the type of database you should choose. If most of the queries you do are simple queries on "primary" keys, then a key-value database or a Document Database may serve you very well. On the other hand, if you do have complex joins that vary widely (for example, your queries are unpredictable), then staying with SQL may be your best option.
- Blob Storage: In case your application, or a subset of application, is using Blob storage in a relational database, then you might be better off using a key-value store like Memcached or Redis. On the other hand, if your application is storing just a structured Java object perhaps profoundly structured but not natively binary, then you may be better off using a document store like Cloudant or MongoDB.
4. DevOps Methodology
Instead of releasing big sets of features, companies are trying to see if small features can be transported to their customers through a series of release trains. This has many advantages, such as quick feedback from customers, better quality of software, etc., which in turn leads to high customer satisfaction. To achieve this, companies are required to:
- Increase deployment frequency
- Lower failure rates of new releases
- Shorten lead-time between fixes
- Faster mean-time to recovery in the event of new release crashing
DevOps fulfils all these requirements and helps in achieving seamless software delivery. Companies like Etsy, Google and Amazon have adopted DevOps to achieve levels of performance that were unthinkable five years ago. They are now accomplishing tens, hundreds or even thousands of code deployments per day while delivering world class stability, reliability and security.
DevOps is the deep integration between development and operations. Here is brief information about the Continuous DevOps life-cycle:
- Development: In this DevOps stage the development of software takes place constantly. In this phase, the entire development process is separated into small development cycles. This benefits the DevOps team to speed up software development and delivery process.
- Testing: QA teams use tools like Selenium to identify and fix bugs in any new piece of code.
- Integration: In this stage, new functionality is integrated with the prevailing code, and testing takes place. Continuous development is only possible due to equally continuous integration and testing.
- Deployment: In this phase, the deployment process takes place continuously. It is performed in such a manner that any changes made any time in the code, should not affect the functioning of high traffic website.
- Monitoring: In this phase, the operation team will take care of the inappropriate system behavior or bugs discovered in production.
5. Infrastructure Architecture
Defining infrastructure requirements for microservices and then provisioning and maintaining infrastructure for each microservice adds a degree of complexity. Infrastructure as Code (“IAC”) is a type of IT infrastructure that operations teams can use to automatically manage and provision through code rather than using a manual process. Companies for faster deployments treat infrastructure like software: as code that can be managed with the DevOps tools and processes. These tools let you make infrastructure changes more easily, rapidly, safely and reliably.
6. Service Mesh
In traditional, monolithic applications the location of resources are well known, relatively static, and found in configuration files (or hard-coded). Even if a monolithic application has been divided into different tiers, for user interface, application logic, database access and others, the location of resources used by the application tend to be well-defined and static. Often times, all tiers of the application are hosted in the same geographical location, even if they are replicated for availability. Connections between the different parts of the application tend to be well-defined, and they don’t tend to change very much.
However, this is not the case for a microservices implementation. Whether that application is built from scratch, or is gradually being built by breaking off functions of a monolithic application, the location of a given service could literally be anywhere. It could be in a corporate data centre, a public cloud provider, or some combination of the two. It could be hosted on bare metal servers, virtual machines or containers—or all of the above…
A given service will usually have more than one instance or copy. Instances of a service can come and go as that service scales up and down under different load conditions. Instances can fail and be replaced by other instances hosted from the same physical location or other locations. You can also have certain instances hosting one version of a service and others hosting a different version. As you go to use these services in your application, you may find they have changed locations without you even knowing.
A services mesh can help you solve the issues and challenges that arise when implementing a microservices application. Each challenge is matched with a generic function, typically provided by a microservices mesh, that can address the challenge.
- Service registry is used to keep track of the location and health of services, so a requesting service can be directed to a provider service in a reliable way. Working hand-in-hand with the service registry is the function of service discovery.
- Service discovery uses the service registry’s list of available services and instances of those services and directs requests to the appropriate instance based on pure load balancing or any other rule that has been configured.
- Service Mesh may also provide automated testing facilities. This gives you the ability to simulate the failure or temporary unavailability of one or more services in your application and make sure the resiliency features you have designed actually work to keep the application functional.
- Two more functions that can help to provide the resiliency are the use of circuit breakers and bulkheads, which are also part of Service Mesh.
Open source mesh functions can be used to solve many of the challenges of implementing microservices.
Benefits of Microservices Architecture
- Scalability: Each microservice can scale independently without affecting other microservices. Thus, it serves an advantage over monolithic application wherein a lot of resources are wasted for scaling unrequired services since they are all packed together into one single deployable Unit.
- Availability: Even if one service fails, other microservices are highly available, and the failed microservice can be rectified very quickly with as minimal downtime as well. Thus, it serves an advantage over monolithic application wherein entire application must be brought down.
- Fault Tolerance: Even if one microservice has faults with regards to, say, a database connection pool getting exhausted. Thus, there is an evident boundary defined with regards to any failure, and unlike in a monolithic approach, other services operate smoothly and hence only a small part of the application is impacted instead of the entire application bogging down.
- Agility: As mentioned above, changes in a particular microservice can be completed and deployed very quickly which makes it a highly suitable architecture for ever-changing business requirements (meaning a highly agile environment).
- Polyglot Persistence: Each microservice can choose its own type of database based on the Use Case requirement. So, in general, the application stack is not tied to a particular database.
- Maintainability: For each business service, a separate microservice is created. Thus, the business code in a microservice is straightforward to understand since it caters to one business functionality. Also, since microservices caters to single business functionalities, the amount of code base is also quite reduced, and this makes it highly maintainable.
- Software Stack agnostic: Since a bigger application is decomposed into a number of smaller microservices, the application is not tied to a single software stack, and thus different software stacks can be used for different microservices.
- Faster Development: Unlike monolithic applications, code changes in microservices can be realized very quickly with changes in business requirements to result in a quicker development cycle.
- Faster Deployment: Since microservice caters to only a single business functionality, the amount of code base is simplified considerable which creates rapid deployment.
- Clear Separation of Business Concerns: Each microservice caters to unique business functionality, and thus there is a very clear separation of business concern between each one of them, and thereby each micro-service can be built in a very robust way.
Conclusion
Microservices architectures fit within agile development environment as breaking a monolith into microservices often aligns with breaking up a silo-oriented team structure into a self-organized and autonomous groups. Real world situations always differ from theory, and the microservices case is no exception. An enterprise should always consider its own business needs, industry threats, and possibilities before deciding to migrate to microservices.
The approaches described earlier are just landmarks to guide you through the migration process. Every business situation is unique and calls for an original solution. Migration to microservices has benefitted fortune 100 companies showing microservices have the transformative potential for all varieties of traditional and modern enterprises. Change is inevitable, and everyone must be ready to embrace it.
About the author
Sameer Paradkar is an Enterprise Architect with 15+ years of extensive experience in the ICT industry which spans across Consulting, Product Development and Systems Integration. He is an Open Group TOGAF, Oracle Master Java EA, TMForum NGOSS, IBM SOA Solutions, IBM Cloud Solutions, IBM MobileFirst, ITIL Foundation V3 and COBIT 5 certified enterprise architect. He serves as an advisory architect on Enterprise Architecture programs and continues to work as a Subject Matter Expert. He has worked on multiple architecture transformation and modernization engagements in the USA, UK, Europe, Asia Pacific and Middle East Regions that presented a phased roadmap to transformation that maximized business value while minimizing costs and risks.
Sameer is part of the IT Strategy & Transformation Practice in AtoS. Prior to AtoS he has worked in organizations like EY - IT Advisory, IBM GBS, Wipro Consulting Services, TechMahindra and Infosys Technologies. He specializes in IT Strategies and Enterprise transformation engagements.

/EN/Reports/Thumbnail-Obsolescence-Gartner.png?width=140&height=100&name=Thumbnail-Obsolescence-Gartner.png)
/EN/White-Paper/EN-IDC-Inforbrief-Application-Rationalization-Portfolio-Management-Thumbnail_v2.png?width=140&height=99&name=EN-IDC-Inforbrief-Application-Rationalization-Portfolio-Management-Thumbnail_v2.png)